那么如果你准备进入深度学习,什么样的GPU才是最合适的呢?下面列出了一些适合进行深度学习模型训练的GPU,并将它们进行了横向比较,一起来看看吧!
太长不看版
截至2020年2月,以下GPU可以训练所有当今语言和图像模型:
RTX 8000:48GB VRAM,约5500美元
RTX 6000:24GB VRAM,约4000美元
Titan RTX:24GB VRAM,约2500美元
以下GPU可以训练大多数(但不是全部)模型:
RTX 2080 Ti:11GB VRAM,约1150美元
GTX 1080 Ti:11GB VRAM,返厂翻新机约800美元
RTX 2080:8GB VRAM,约720美元
RTX 2070:8GB VRAM,约500美元
以下GPU不适合用于训练现在模型:
RTX 2060:6GB VRAM,约359美元。
在这个GPU上进行训练需要相对较小的batch size,模型的分布近似会受到影响,从而模型精度可能会较低。
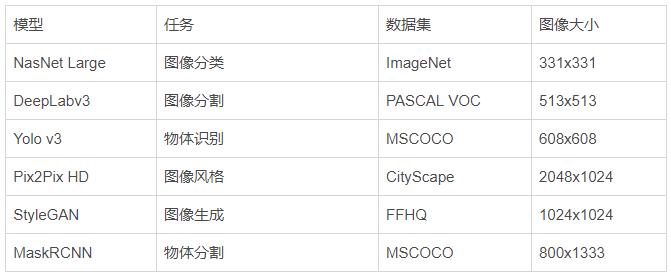
图像模型
内存不足之前的最大批处理大小:

性能(以每秒处理的图像为单位):

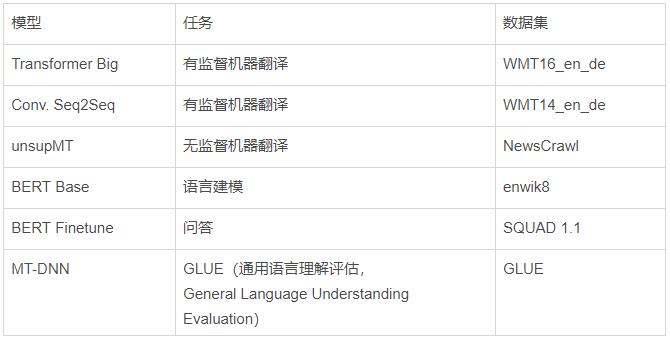
语言模型
内存不足之前的最大批处理大小:
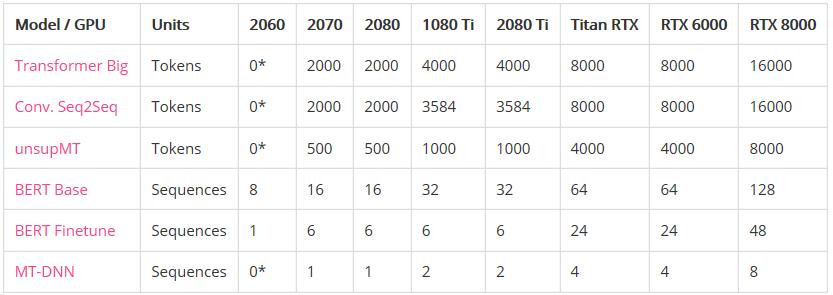
性能:
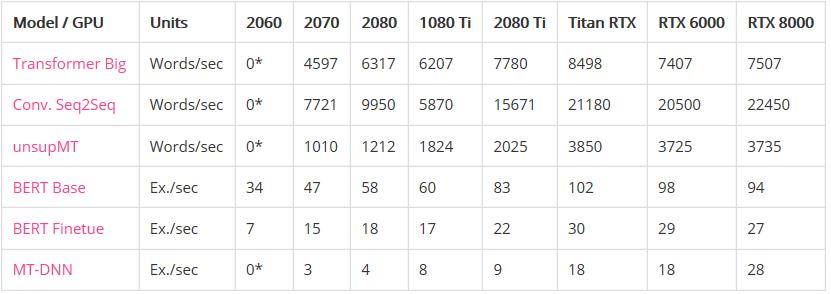
使用Quadro RTX 8000结果进行标准化后的表现
图像模型
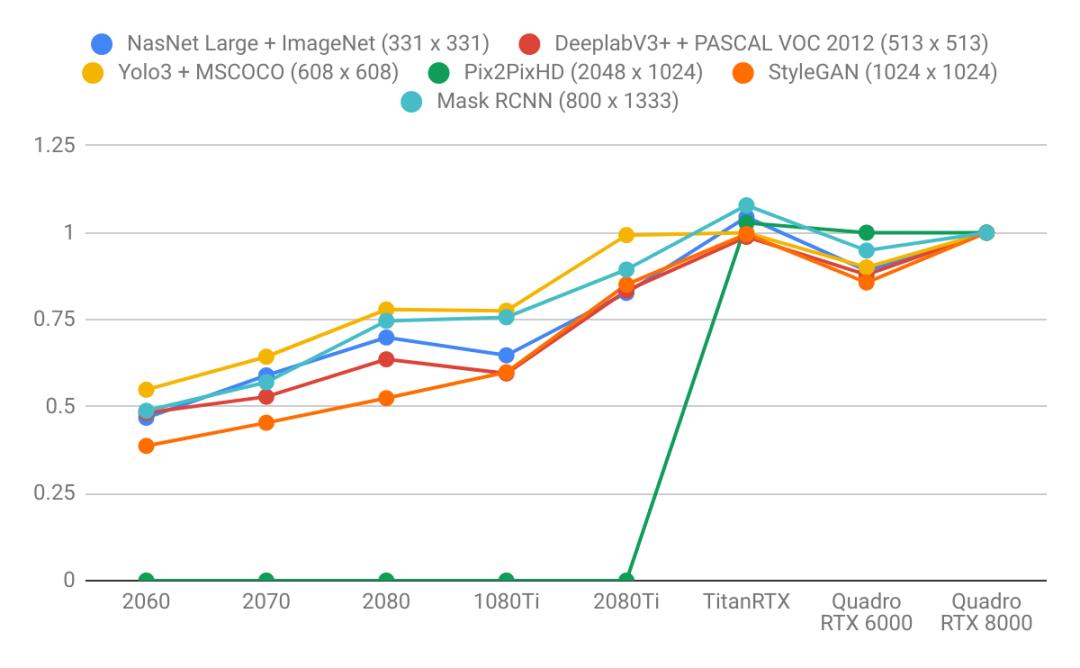
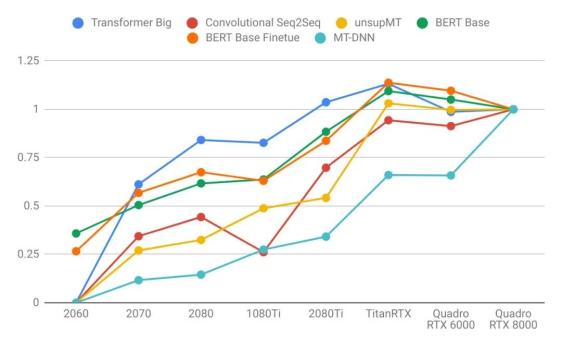
语言模型比图像模型受益于更大的GPU内存。注意右图的曲线比左图更陡。这表明语言模型受内存大小限制更大,而图像模型受计算力限制更大。
具有较大VRAM的GPU具有更好的性能,因为使用较大的批处理大小有助于使CUDA内核饱和。
具有更高VRAM的GPU可按比例实现更大的批处理大小。只懂小学数学的人都知道这很合理:拥有24 GB VRAM的GPU可以比具有8 GB VRAM的GPU容纳3倍大的批次。
比起其他模型来说,长序列语言模型不成比例地占用大量的内存,因为注意力(attention)是序列长度的二次项。
GPU购买建议
RTX 2060(6 GB):你想在业余时间探索深度学习。
RTX 2070或2080(8 GB):你在认真研究深度学习,但GPU预算只有600-800美元。8 GB的VRAM适用于大多数模型。
RTX 2080 Ti(11 GB):你在认真研究深度学习并且您的GPU预算约为1,200美元。RTX 2080 Ti比RTX 2080快大约40%。
Titan RTX和Quadro RTX 6000(24 GB):你正在广泛使用现代模型,但却没有足够买下RTX 8000的预算。
Quadro RTX 8000(48 GB):你要么是想投资未来,要么是在研究2020年最新最酷炫的模型。
附注
图像模型:
https://lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
志愿者介绍
后台回复“志愿者”加入我们

原标题:《2020年深度学习最佳GPU一览,看看哪一款最适合你!》
